You can see an index of all the posts in this series: go to index.
If you want to review where I got to by this point, here are the starter files from the end of the previous post: loops.
In the previous post, I used two types of loop, a while loop and a for loop, to display the number of phrases requested by the user. I also ended by considering a challenge to use a do … while loop to achieve the same thing. Here’s my solution with changes highlighted:
/*******
* Buzzword
*
* A program to create amusing fake jargon
*******/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <errno.h>
// Function declarations
void displayUsageAndExit();
int main(int argc, const char * argv[]) {
int numberOfPhrases = 0;
if (argc == 1) {
// There was no argument so default to one phrase
numberOfPhrases = 1;
} else if(argc != 2) {
// An incorrect number of arguments was given, so quit with usage message
displayUsageAndExit();
} else {
// A single argument was given, so attempt to convert it to an integer
errno = 0;
char * inputStr;
long inputNum = strtol(argv[1], &inputStr, 10);
if(errno == ERANGE || *inputStr != '\0' || inputNum < 1 || inputNum > 99) {
// The argument could not be interpreted as an integer in the required range, so quit with usage message
displayUsageAndExit();
}
numberOfPhrases = (int) inputNum;
}
// Temporary statement to check validation code by showing the number of phrase requested
// printf("\nThe user asked for %i phrase(s)\n", numberOfPhrases);
// Display the instructions
printf("Buzzword Generator\nBased on a program from Creative Computing, Morristown, New Jersey\n\n\nThis program prints highly acceptable phrases in 'educator-speak' that you can work into reports and speeches. Whenever a question mark is printed, type a 'Y' for another phrase or 'N' to quit.\n\n\nHere's the first phrase:\n");
// Create three lists of words
const char * adjectives1[] = {"ability", "basal", "behavioral", "child-centered", "differentiated", "discovery", "flexible", "heterogeneous", "homogenous", "manipulative", "modular", "tavistock", "individualized" };
const char * adjectives2[] = {"learning", "evaluative", "objective", "cognitive", "enrichment", "scheduling", "humanistic", "integrated", "non-graded", "training", "vertical age", "motivational", "creative"};
const char * nouns[] = {"grouping", "modification", "accountability", "process", "core curriculum", "algorithm", "performance", "reinforcement", "open classroom", "resource", "structure", "facility", "environment"};
// Seed the random number generator
srand((unsigned int)time(NULL));
// Display the number of randomly generated phrases requested by the user
int i = 0;
do {
printf("\n%s %s %s\n\n", adjectives1[rand() % 13], adjectives2[rand() % 13], nouns[rand() % 13]);
i++;
} while (i < numberOfPhrases);
return EXIT_SUCCESS;
}
void displayUsageAndExit() {
printf("\nUsage: BUZZWORD number_of_phrases\nWhere number of phrases is a whole number from 1 to 99");
exit(EXIT_FAILURE);
}
The main thing to watch out for with do … while loops is that the body of the loop will always be executed at least once, regardless of the condition. For example, if, for some reason, numberOfPhrases was 0 when this loop was first reached, the body of the loop would be executed once, printing a single phrase. Only at that point would the condition be checked and no further iterations of the loop would occur. Contrast this to the while loop, where the condition would have been checked as soon as the loop was reached, and the body of the loop would never have been executed.
A common mistake with do … while loops is forgetting to put the semicolon after the closing parenthesis for the condition, so I need to watch out for that.
OK after all that hard work with command line arguments, I am now going to dispense with them. Instead of the user entering the number of phrases on the command line, I am now going to replicate the behaviour of the original BASIC program and get the user to press a key at the end of each phrase. If they enter Y they will get another phrase. If they enter anything else the program will end.
Before I begin to make those changes, it’s time to introduce another advantage of using a source control system. What I’ve got here is a functional and acceptable program that takes a command line argument and generates the requested number of phrases. It seems a shame to throw all that code away, especially as I may eventually decide I prefer this version. Fortunately I don’t have to choose one or the other – I can have both. I can use a version control feature called branching. Just as it sounds this is used to create a branch in my source history so that I can effectively maintain two or more variants of my program.
The first thing to do is make sure I’ve committed my changes and pushed them to GitHub. When I set up git it created a single branch called master. I can also set up additional branches. I might want to do this, for example, if I want to work on an experimental feature and I’m not sure yet if I will keep this feature as a part of my main build. To create a new branch, in a terminal app, I navigated to the folder with my buzzword source code and entered git checkout -b user-requests-each-new-phrase.

The git checkout command is one I haven’t use previously. It’s used to switch between branches of my repository or to restore the working tree files. If I use it with the -b option, it will create a new branch – in this case named user-requests-each-new-phrase, Branch names should be descriptive of the feature the branch is focused on without getting over long.
From this point, the changes I make will be to the user-requests-each-new-phrase branch. I’ll continue to work on this branch for the moment, and later I’ll demonstrate the advantage of doing things this way.
First though, I’ll have a quick look at the BASIC program to see how it handles getting this user input.
110 PRINT A$(INT(13*RND(1)+1));" "; 120 PRINT A$(INT(13*RND(1)+14));" "; 130 PRINT A$(INT(13*RND(1)+27)) : PRINT 150 INPUT Y$ : IF Y$="Y" THEN 110 ELSE GOTO 999 . . . 999 PRINT "COME BACK WHEN YOU NEED HELP WITH ANOTHER REPORT!":END
Lines 110 to 130 should be familiar, as I examined them in an earlier post. These are the lines that generate and display a random phrase.
Line 150 has two statements. The first statement, INPUT Y$, displays a question mark, then waits for the user to type in a response and hit enter. The response is then saved in the specified string variable (Y$).
The next statement on this line should look a little familiar, as it is BASIC’s version of an IF command. The condition is Y$=”Y”, in other words it checks to see if the user has entered the single letter Y. Notice that BASIC uses a single = sign for both assignment and equivalence operations. It can distinguish between the two based on context.
The part of the IF statement following the keyword THEN is equivalent to what’s in the braces in the C if statement. In this case it’s just a single number, 110. In BASIC, when a single number is used in this context, it means continue execution from this line. So, if the condition is true (i.e. the user has entered Y), control will return to the lines that display a random phrase.
Like C, BASIC also has an ELSE command for indicating code that should be run if the condition is not true. The code that follows this is the equivalent of the code that would be placed within the braces following the C else command. The statement to be executed here is GOTO 999. As you might have already guessed, this causes execution to continue from line 999.
The first statement in line 999 displays a final message to the user. In the second statement, END is BASIC’s equivalent of C’s exit function – it cause program execution to end.
I made the following changes to the program (highlighted):
/*******
* Buzzword
*
* A program to create amusing fake jargon
*******/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(int argc, const char * argv[]) {
// Display the instructions
printf("Buzzword Generator\nBased on a program from Creative Computing, Morristown, New Jersey\n\n\nThis program prints highly acceptable phrases in 'educator-speak' that you can work into reports and speeches. Whenever a question mark is printed, type a 'Y' for another phrase or 'N' to quit.\n\n\nHere's the first phrase:\n");
// Create three lists of words
const char * adjectives1[] = {"ability", "basal", "behavioral", "child-centered", "differentiated", "discovery", "flexible", "heterogeneous", "homogenous", "manipulative", "modular", "tavistock", "individualized" };
const char * adjectives2[] = {"learning", "evaluative", "objective", "cognitive", "enrichment", "scheduling", "humanistic", "integrated", "non-graded", "training", "vertical age", "motivational", "creative"};
const char * nouns[] = {"grouping", "modification", "accountability", "process", "core curriculum", "algorithm", "performance", "reinforcement", "open classroom", "resource", "structure", "facility", "environment"};
// Seed the random number generator
srand((unsigned int)time(NULL));
char input; // This will store the character entered by the user
// Display random phrases while user keeps requesting them
do {
printf("\n%s %s %s\n\n", adjectives1[rand() % 13], adjectives2[rand() % 13], nouns[rand() % 13]);
printf("?");
scanf("%c", &input);
printf("You entered: %c\n", input);
} while (input == 'y');
printf("Come back when you need help with another report!\n");
return EXIT_SUCCESS;
}
Note that I’ve removed:
- the line to include the errno library
- all the lines at the beginning of the main function (to get and validate command line arguments) that came before the line to display the instructions
- the displayUsageAndExit function declaration and definition.
Now let’s have a look at what’s happening in the new code. On line 24 I set up a char variable called input. This will be used to hold the character that is entered by the user. I’ve still got the line that displays a random phrase, on line 28 and it’s still within a do … while loop, from line 27 to line 33. Instead of checking a counter, as it did before, this condition checks to see whether input holds the letter ‘y’, which indicates that the user wants to see another phrase. If it doesn’t hold ‘y’, I display a farewell message on line 35 before ending the program on line 37. This should all be familiar. But how do I get the letter the user enters and put it into input?
That’s taken care of by the scanf function in line 31, which is short for scan formatted and is part of the standard input-output library, stdio. If you think scanf looks mighty similar to printf, you’d be right. While printf sends data to the standard output, scanf reads data from the standard input, which in this case is the keyboard. Like printf, scanf takes a format string with conversion specifiers, and then one further parameter to match each conversion specifier. My string is very simple, it’s just “%c”, which means read a single character into the variable I give you. This is followed by the name of the variable, input.
Did you notice that & before the variable name? You’ve seen it once before, in the command line version of Buzzword. When I use a variable name on its own, as I do in a printf command, C interprets this as meaning I want the value of the variable. But scanf doesn’t care what the current value of the variable is, it wants to put a new value there – the one that it reads from the standard input. So instead of using the variable name on its own, we prefix it with the reference operator, &. When C sees a variable name prefixed with &, instead of providing the value of the variable, it provides the variable’s address in memory. The scanf function then stores the value it reads at this address, which is equivalent to setting the variable to that value.
I’ll try it out. I’ve added a temporary printf command on line 32 so I can see what character has been captured by scanf. I saved and compiled and ran the program (remembering I don’t need any command line arguments for this version).
I saw the instructions, my first phrase and then a prompt: ?. The program has now paused, waiting for me to enter some characters:
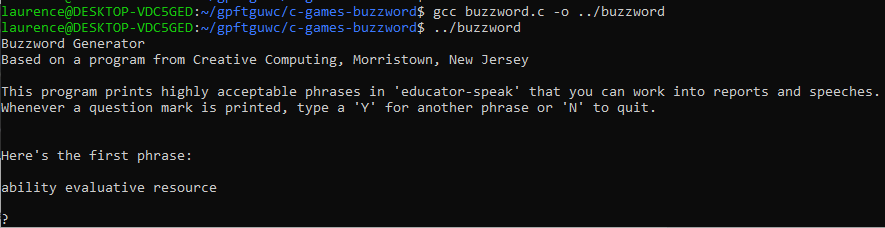
OK let’s try a negative response first. I typed n and then hit the enter key. The program displayed the farewell phrase and then ended.

Great! That’s exactly what I was expecting. I tried running again, and this time I tried a positive response b typing y and hitting enter. This is what I got:
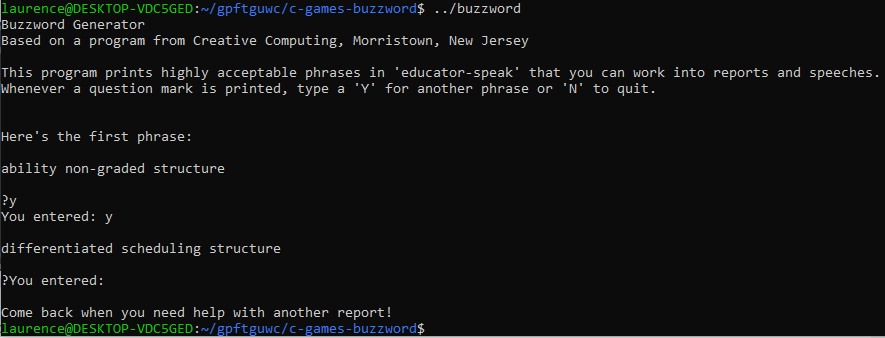
Woah! What happened there? The program displayed another phrase as it should, but then, instead of stopping and waiting for my input again, it flaked out and ended. To understand why this was, I need to look a bit closer at what scanf does. When I type, the terminal app collects the characters until I press enter. Then it sends all the characters it has gathered, including the enter (which is interpreted as a newline, \n) to standard input, or stdin as it’s referred to in C.
At this point my scanf function starts processing it. The scanf function takes characters from stdin and tries to interpret them based on the conversion specifiers I’ve given it. In this case I’ve given it just one conversion specifier, which is %c for a character. The first character it encounters is the y I typed. So scanf dutifully copies the y character into my variable called input and let’s the rest of my program go about its business. So it displays the entered character on line 32, then on line 33 it checks to see if it is equal to ‘y’, which it is, so it returns to the top of the loop on line 27. In the loop on line 28 it displays another random phrase, then on line 30 it displays another prompt.
At this point you might expect that the scanf function on line 31 would hang around and wait for me to enter something else. But it doesn’t. Why? Because when it looks at stdin, it finds that stdin is not empty – it still has the \n character I entered last time when I hit the enter key. So it dutifully copies the \n character to my variable, input, and control passes to the next line. This time when it gets to the loop condition, input contains \n, which is not equal to ‘y’, so the program ends.
This is not what I want at all. I want my program to ignore the \n characters and just process the letters I type. Well there is a solution. I changed line 31 so that there is a single space between the opening quote and %c, like this:
scanf(" %c", &input);
What this does is tell scanf, “look, I’m just not interested in any white space that comes before other characters. So if you find any spaces, tabs, newlines or other characters of that ilk, just throw them away. Thanks.”
I saved, compiled and ran the program again. This time, when I entered y, I got another phrase and the program waited for me to enter another character. I continued entering y until I was tired of seeing new phrases and then entered n (although it could have been any character other than y) to end the program.
Hurrah, so I’ve solved the problem right? Well, I’ve solved a problem. But all is still not well in scanf land. To show you what I mean, I tried running the program again and entered yes instead of y. This is what I saw:
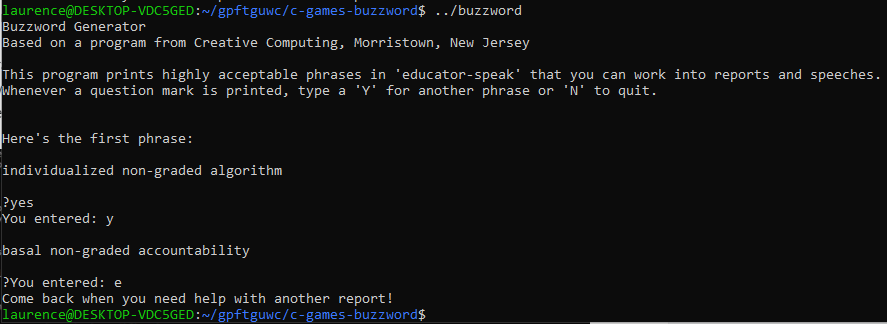
Do you see what happened here? The first time through, scanf reads the y into input, but leaves the e and the s in stdin. The next time through, scanf sees that stdin isn’t empty and reads the e into input. Because e does not equal ‘y’, the program ends.
So what can I do about this? Well the fundamental challenge with scanf is that it’s a messy eater – it takes what it wants from stdin and leaves the half-chewed remains on the plate. What I really need is a way to get everything from stdin, so I start with it empty each time. I made the following changes to my code (I’m only showing the affected section from now with changes highlighted):
// Seed the random number generator
srand((unsigned int)time(NULL));
char rawInput[80]; // This will hold the raw input entered by the user
char input; // This will store the character entered by the user
// Display random phrases while user keeps requesting them
do {
printf("\n%s %s %s\n\n", adjectives1[rand() % 13], adjectives2[rand() % 13], nouns[rand() % 13]);
printf("?");
fgets(rawInput, sizeof(rawInput) / sizeof(rawInput[0]), stdin);
sscanf(rawInput, " %c", &input);
printf("You entered: %c\n", input);
} while (input == 'y');
In line 24 I’ve added another variable, a character array called rawInput, with 80 elements. This is where I will store everything the user types.
Line 32 introduces a new function, fgets, which is part of the stdio library. The fgets function reads a stream of characters from a file stream and stores them in a character array. I haven’t yet introduced the concept of a file stream, but for now, all you need to know is that stdin is a type of file stream.
The fgets function takes three parameters. The first is the character array where fgets should store the characters it reads. I’ve given it the name of the array I set up in line 24, rawInput.
The second is the maximum number of characters that fgets should read. It needs to know this, because otherwise it could potentially write more characters than there is space for in the array. Here I’ve used sizeof(rawInput) / sizeof(rawInput[0]) to get that number. Although sizeof() looks like a function, it’s actually an operator. It returns the size of its operand in bytes.
What I’m actually doing here is first getting the total number of bytes occupied by the array. I’m then dividing that by the number of bytes occupied by a single element to get the number of elements in the array. Note that a char variable normally occupies a single byte, so I’d get exactly the same result using just sizeof(rawInput). However, it’s always a good idea never to assume anything with C, especially if I am planning to compile my code on various different systems.
So here it will return 80, which is the size of the character array rawInput. You might be wondering why I didn’t just type 80 – after all I have only to look at line 24 to see that’s what size the array is. The reason for not doing so, is that at a later point I might decide to change the size of this array. If I do that, I have to remember to change the number, not just in the initialiser in line 24, but also here in the fgets function call. This is bad practice, because it’s too easy to forget to change both of them. By using sizeof, I know that the value returned is always going to be correct, no matter how often I change the size of the array in line 24.
The third parameter is the file stream to read from. In this case I want to read from stdin.
This function will now read the characters I type up to and including enter (\n) or the first 80 characters I type, whichever comes sooner. So what would happen to any characters over 80? Well, they’d stay in stdin and be read next time round. Note that this does mean a really determined user could still cause the program to terminate by typing a very long phrase over 80 characters, but this will be more than enough to look after the users who simply type yes or yep or yeah or yea instead of y. OK, so I’ve now got the characters the user has entered, but how do I determine if the first of these characters is y?
You’ll notice on line 33 that I have something that looks remarkably similar to my scanf function. Whereas scanf reads from stdin, sscanf, which is also part of the stdio library, reads from a string – that’s what the extra s at the beginning stands for. It takes at least three parameters. The first is the string to be processed. I’ve given it the name of my character array, rawInput here. The remaining parameters are the same as the parameters of scanf – a string literal containing the conversion specifiers, and then, for each conversion specifier, the address of a variable where the output is to be stored.
You might be wondering why I’ve even bothered to use sscanf. Why not just get the first character using rawInput[0]? The answer is white space once again. I can’t guarantee that the user hasn’t put spaces or tabs before typing y. I can use the same trick with sscanf, as I did with scanf – adding a single space before the conversion specifier %c to force sscanf to ignore any white space.
OK I tried saving, compiling and running my program again and found that entering y, yes or yellow-bellied son of a gun all resulted in me getting another phrase for my money.
Since my input routine now works as I need it to, I can now remove line 34, which uses printf to show the character entered. Am I done? Almost. There’s just one more nicety I have to take care of.
When I tried running my program and entering Y (an upper case y) – it dumped me straight out on my ass. I need it to serve up another phrase regardless of whether the y is upper or lower case. I should be able to make a simple modification to the loop condition, which is now on line 34, to take care of this.
I changed line 34 to:
} while (input == 'y' || input == 'Y');
Having made that change, then saved, compile and rerun the program, I tried it with both an upper case and lower case y to satisfy myself that it worked.
Yay! I’ve completed this first game in C. I just had to make sure I committed my changes and pushed them to GitHub.
Before I move on to my next project, I promised I’d talk about the benefits of branching my code in GitHub. At the moment, I have two branches:
- My master branch contains the version of the program that uses command line arguments
- My user-requests-each-new-phrase branch contains the version of the program that requires the user to enter y or Y after each phrase to generate another phrase
It’s the latter branch that I currently have in my local file system. I can confirm this by entering git status to see that it confirms the repository is currently on the “user-requests-each-new-phrase” branch:

Let’s say, for the sake of argument, that Idecide to stop working on that branch for now and continue working on my master branch. It’s very easy to restore the files from that branch. I simply enter git checkout master:

This will switch to the master branch and confirm that this has happened.
Ta da! I’ve got my original version back and can recompile it. If I want to switch back to the other branch at any point, I make sure that I’ve committed any changes to master and enter git checkout user-requests-each-new-phrase. But while I have the master branch, I’ll first do a little bit of work on it.
There’s a small error in this version of the program. It still displays the instruction about entering y to request a new phrase, which isn’t applicable to this command line version. Also, instead of displaying “Here’s your first phrase”, it would be better if we told the user how many phrases the program was about to display.
First I deleted lines 39 and 40 that displayed how many phrases were requested, then I made the following highlighted changes to the code:
/*******
* Buzzword
*
* A program to create amusing fake jargon
*******/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <errno.h>
// Function declarations
void displayUsageAndExit();
int main(int argc, const char * argv[]) {
int numberOfPhrases = 0;
if (argc == 1) {
// There was no argument so default to one phrase
numberOfPhrases = 1;
} else if(argc != 2) {
// An incorrect number of arguments was given, so quit with usage message
displayUsageAndExit();
} else {
// A single argument was given, so attempt to convert it to an integer
errno = 0;
char * inputStr;
long inputNum = strtol(argv[1], &inputStr, 10);
if(errno == ERANGE || *inputStr != '\0' || inputNum < 1 || inputNum > 99) {
// The argument could not be interpreted as an integer in the required range, so quit with usage message
displayUsageAndExit();
}
numberOfPhrases = (int) inputNum;
}
// Display the instructions
printf("Buzzword Generator\nBased on a programme from Creative Computing, Morristown, New Jersey\n\n\nThis programme prints highly acceptable phrases in 'educator-speak' that you can work into reports and speeches.\n\n");
if (numberOfPhrases == 1) {
printf("Here's your phrase:");
} else {
printf("Here are your %i phrases", numberOfPhrases);
}
// Create three lists of words
const char * adjectives1[] = {"ability", "basal", "behavioral", "child-centered", "differentiated", "discovery", "flexible", "heterogeneous", "homogenous", "manipulative", "modular", "tavistock", "individualized" };
const char * adjectives2[] = {"learning", "evaluative", "objective", "cognitive", "enrichment", "scheduling", "humanistic", "integrated", "non-graded", "training", "vertical age", "motivational", "creative"};
const char * nouns[] = {"grouping", "modification", "accountability", "process", "core curriculum", "algorithm", "performance", "reinforcement", "open classroom", "resource", "structure", "facility", "environment"};
// Seed the random number generator
srand((unsigned int)time(NULL));
// Display the number of randomly generated phrases requested by the user
for (int i = 0; i < numberOfPhrases; i++) {
printf("\n%s %s %s\n", adjectives1[rand() % 13], adjectives2[rand() % 13], nouns[rand() % 13]);
}
return EXIT_SUCCESS;
}
void displayUsageAndExit() {
printf("\nUsage: BUZZWORD number_of_phrases\nWhere number of phrases is a whole number from 1 to 99");
exit(EXIT_FAILURE);
}
Let’s say I think on things for a while and realise that perhaps the best user experience would be a combination of the two branches – a program that gives people the choice of specifying a precise number of phrases by entering a command-line argument or requesting phrases one by one.
You might be forgiven for thinking that this means I have to painstakingly rebuild all the changes I’ve made in the user-requests-each-new-phrase branch in the master version. Fortunately with Git I can merge two branches back into a single branch. Here’s how I do it.
First I commit the changes I’ve just made to the master branch. Now, in the terminal app, I enter git merge user-requests-each-new-phrase. The git merge command will cause Git to try and create a single code base by merging the current branch with the branch I specified in the command. In some cases, Git is able to merge the files automatically. In this case, however, I’ve done further work on our master branch since I created the user-requests-each-new-phrase branch, which means there are conflicts that Git can’t resolve. So I see a message like this:

So how do I even see what these conflicts are, let alone fix them?
I opened buzzword.c in my text editor and saw this:
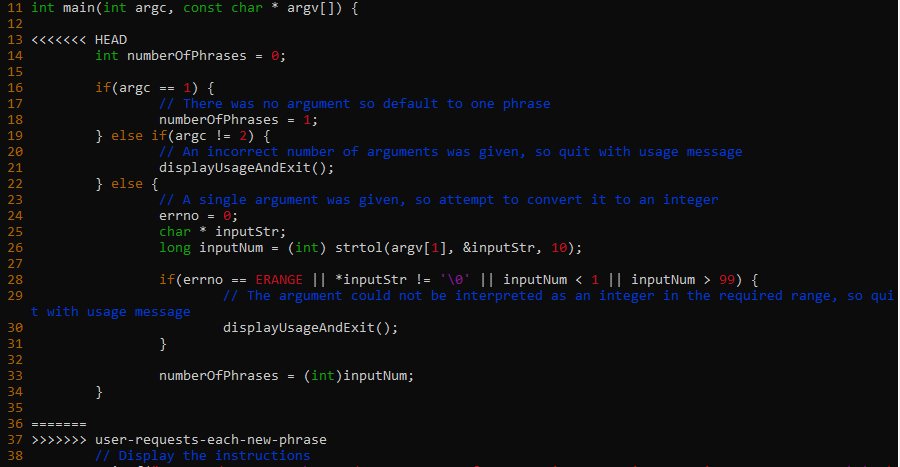
Wherever there’s a conflict, Git will include versions of the conflicting lines from both branches. The start of the lines from the branch being merged into will be indicated by <<<<<<< HEAD and the end will be indicated by =======. This will be followed by the lines from the branch being merged, which will end with >>>>>>> user-requests-each-new-phrase (or whatever the branch is named). I might find several blocks of code that are marked in this way.
My job is now to review each of the marked blocks and decide which version I want, then edit the file appropriately. In the case above I can see that there is no code between the ======= and >>>>>>> user-requests-each-new-phrase. That’s because I deleted all these lines in that branch. So here Git is basically saying “Hey, you deleted all these lines of code in your user-requests-each-new-phrase branch, but you still have them in more recent versions in your master branch, so now I’m not sure whether you want them or not”.
In this case, because I want to combine the command line functionality with the user input functionality, I want to keep these lines. So I can simply delete the extra lines Git has added to indicate the conflict.
So now I have my “best of both worlds” version, but if I try to compile and run it at the moment it’s going to break. There’s a little bit of work I’ll need to do to get the two behaviours to play nicely with each other. So here’s a final challenge for me (this one is a bit tougher than those I’ve tackled before). I need to make changes to the code so it runs correctly and meets the following requirements.
- The program should take an optional single command line argument that is an integer number between 1 and 99.
- If the user enters more than one command line arguments or a single command line argument that is not an integer between 1 and 99, then the program should display a suitable usage message and stop.
- If the user enters a valid command line argument
- The program should display the message “Here are your x phrases”, where x is the number of phrases requested. If the user requested a single phrase, show the message, “Here is your phrase: “.
- This should be followed by the number of phrases requested, each on its own line.
- If the user does not enter a command line argument
- the program should first display instructions to the user on how to request a new phrase.
- It should then display the message “Here is your first phrase:” followed by a single phrase on a newline.
- It should then display a question mark and wait for the user to enter a response.
- If the response starts with y or Y it should show a new phrase
- In both cases, once the requested number of phrases have been shown or the user has declined another phrase, the program should show the sign off message: “Come back when you need help with another report!” and then stop.
In the newly merged file, I have most of the code I need to do this, but I do need to think carefully about how I will handle the two modes. It’s always a good idea to plan my approach on paper first before I start modifying my code, for example, using a flowchart.
In the next post, I’ll show you my solution.
Be First to Comment